Con il titolo ho decisamente esagerato, ma qualcosa di buono lo dovreste trovare.
Il contenuto di questo articolo nasce dall’aver incontrato più volte situazioni dove si è ragionato solo all’ultimo momento sui dati da raccogliere e su come renderli utili.
La dashboard ralizzata con i dati reali può essere vista qui.
- Immaginiamo un impianto
- Dati logistici di processo
- Raggruppamenti
- Raggruppamento per ordine lavoro
- Raggruppamento per trattamento
- Fine dell’ordine lavoro
- Percorsi di trattamento
- Dati tecnici di processo
- Formato del log
- Ordini lavoro multipli
Immaginiamo un impianto
Immaginiamo un impianto di verniciatura, galvanizzazione, cottura, …, dove un supporto caricato a mano entra con i pezzi da trattare e ne esce dopo un tot di tempo con i pezzi trattati per essere scaricato.

Facciamo ora alcune semplici considerazioni sui dati che possiamo raccogliere in automatico e utilizzare per valutare il processo di trattamento.
Queste considerazioni che possono aiutare chi realizza l’impianto a fornire i dati in modo corretto e a chi produce KPI per avere una base di partenza.
Nei trattamenti abbiamo tipicamente degli ordini lavoro (O1, O2, O3, …) composti da una serie di pezzi (uniformi o meno) che devono essere trattati con uno specifico trattamento (T1, T2, T3, …).
Un trattamento (ricetta, programma, …) è un insieme di parametri: colori, temperature, tempi, pressioni, lavaggi, …
I pezzi sono caricati su supporti (S1, S2, S3, …) che possono essere bilancelle, ganci, rastrelliere e altro. Ogni supporto può contenere una combinazione di pezzi provenienti da ordini lavoro differenti.
I trattamenti effettuati dall’impianto possono essere diversi e un supporto è soggetto ad un solo tipo di trattamento durante il suo ciclo quindi mettere ordini lavoro differenti sullo stesso supporto significa che devono essere oggetto dello stesso trattamento.
Si possono creare famiglie di prodotti che presso l’impianto saranno trattati allo stesso modo da utilizzare per la pianificazione.
Dati logistici di processo
Un supporto S porta con sé una serie di dati che devono essere forniti dall’impianto (in parte inseriti dall’operatore ed in parte raccolti durante il trattamento).
Alcune informazioni sono “passanti”, nel senso che non interessano il trattamento ma devono essere “trasportate” tra l’ingresso e l’uscita.
Dati di un supporto S:
- Codici degli ordini lavoro caricati (O1, O2, …)
- Codice del trattamento T effettuato (che vale per tutti gli ordini lavoro caricati)
- Inizio del caricamento pezzi (richiamo del supporto nella postazione di carico)
- Inizio di avvio trattamento
- Fine del trattamento
- Fine dello scarico
- Errori
Se l’impianto non è costruito per raccogliere questo tipo di dati (ad esempio perché un supporto scaricato va diretto alla postazione di carico e quindi il “tempo di carico” non è determinabile) sarà necessario o rinunciare a certi parametri statistici o ricavarli in modo indiretto.
I dati derivati direttamente saranno:
- Tempo di carico (inizio avvio trattamento-inizio carico)
- Tempo di ciclo del trattamento (fine trattamento-inizio trattamento)
- Tempo di ciclo totale (fine scarico-inizio carico)
- Tempo di scarico (fine scarico-fine trattamento)
Da notare che questo approccio è agnostico rispetto a quello che avviene all’interno dell’impianto.
Con i dati dei singoli supporti si possono valutare valori medi e gli andamenti nel tempo.
Tutti gli elementi visuali mostrati sotto, sono stati realizzati con Google Looker e i dati reali di un impianto in pochi minuti.
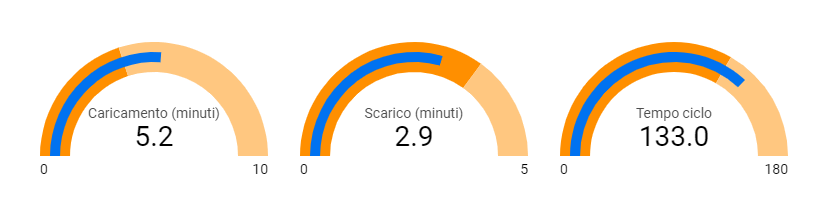
Iniziamo con il visualizzare degli indicatori semplici ma interessanti. Questi cruscotti sono tipicamente dotati di un selettore dell’intervallo temporale. Un primo insieme di numeri sarà il conteggio dei supporti entrati nell’impianto e i tempi.

Possono essere visualizzati in modo più significativo con indicatori grafici, dove si evidenzia anche il limite tra valori buoni e non buoni.
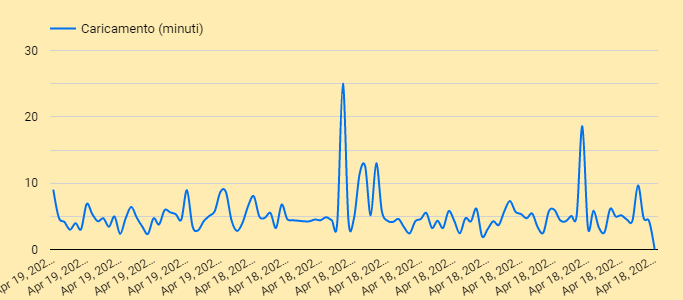
Passando ai grafici cronologici, due sono quelli che interessano.
Il grafico sequenziale di un certo valore (ad esempio il tempo di carico) che mostra il dato raccolto senza tenere conto dei momenti di non funzionamento.
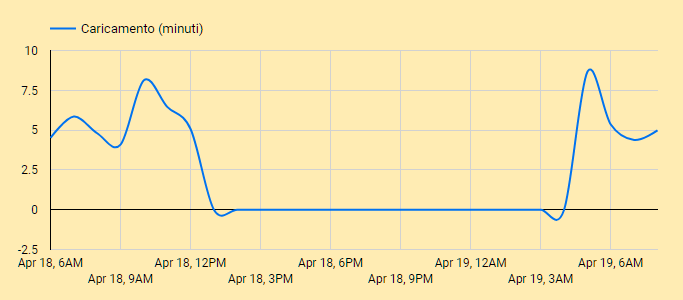
Il grafico “time series”, mostra lo stesso valore (tipicamente mediato), ma rispetto al tempo reale, quindi con i momenti di fermo e di lavoro.
Raggruppamenti
I dati possono successivamente essere valutati per raggruppamenti.
Raggruppamento per ordine lavoro
Il raggruppamento più ovvio è per ordine lavoro, tenendo in conto che più ordini lavoro sono attivi contemporaneamente.
- Inizio di un ordine lavoro (tempo del primo supporto che contiene dei pezzi dell’ordine)
- Fine di un ordine lavoro (deve quasi sempre essere indicato dall’operatore – vedi oltre)
- Numero di supporti utilizzati (valido se i supporti utilizzati in modo misto non sono rilevanti, ad esempio solo il primo e l’ultimo che raccordano ordini lavoro in successione)
Queste informazioni sono memorizzate nell’ordine lavoro e utilizzate per la logistica, per l’analisi a posteriori, …
Un esempio di rappresentazione tabellare divisa per ordine lavoro, con i tempi di carico e scarico ed il loro target (riga verticale) è questa:
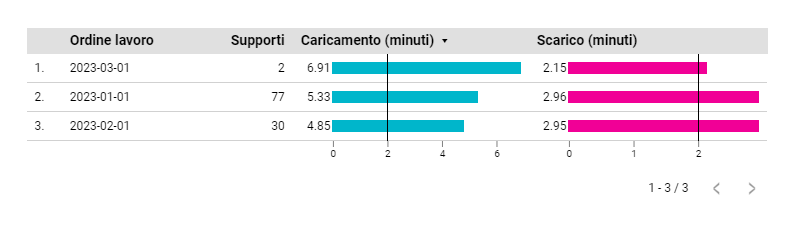
Raggruppamento per trattamento
Il raggruppamento per trattamento rende più uniforme la valutazione del ciclo di trattamento, specie se trattamenti diversi hanno tempi significativamente differenti e non comparabili.
Il caso classico si verifica nella galvanica dove i supporti possono essere immersi in un numero variabile di vasche e per un tempo variabile a seconda del processo.
In un impianto di trattamento termico, differenti programmi sono rapresentati dalle diverse temperature e tempi di “cottura”.
In un impianto di verniciatura, il programma sarà relativo al lavaggio, al colore e alla cottura finale.
Fine dell’ordine lavoro
La fine del trattamento di un ordine lavoro non può essere con sicurezza determinata in modo automatico perché non si conosce se e quando altri pezzi dell’ordine saranno trattati. Infatti, è molto raro che sia possibile tracciare i singoli pezzi caricati e quindi avere una chiara idea dell’avanzamento.
Ci sono però approcci da adottare:
- Se sono passate più di N ore dall’ultimo supporto con un ordine lavoro O lo si considera l’ultimo e il tempo di scarico determina la chiusura dell’ordine
- Si può stabilire il numero medio di supporti necessario per una certa commessa e quindi avere un approssimativo stato di avanzamento (molto difficile – ma costruibile con uno storico)
Percorsi di trattamento
Alcuni impianti, per uno stesso trattamento T, possono applicare internamente dei “percorsi” che non cambiano il risultato finale, ma sono utilizzati per ottimizzare il processo (ad esempio mettere in parallelo alcune fasi lente).
Un supporto con i propri pezzi può essere lavorato con il trattamento T ed un percorso P1 ed un altro con lo stesso trattamento T ma il percorso P2. La registrazione del percorso è importante per alcuni motivi:
- Se ci sono difetti di qualità che si ripetono e sono riconducibili ad un percorso si può analizzare solo quello
- Raggruppando per commessa/trattamento/finestra temporale è utile sapere il rapporto tra i percorsi utilizzati
In generale, se un percorso è preferibile ad un altro, avere una chiara idea del loro “bilanciamento” è fondamentale. Nell’esempio qui sotto supponiamo di avere due percorsi e che il giusto valore sia 30% nel percorso 1 e 70% nel percorso 2. Questo rapporto è indicato dalla fascia arancione, mentre quella blu mostra chiaramente che siamo completamente fuori scala.
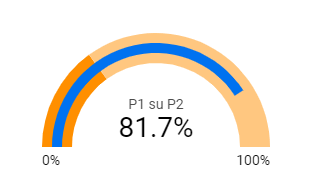
Dati tecnici di processo
Ogni impianto può raccogliere numeri dati tecnici di processo (tempi, temperature, pressioni, …), ma questi non sono “agnostici” e vanno analizzati caso per caso recuperando solo quelli che hanno un significato nel loro andamento storico (SPS), o come dato per la certificazione del trattamento fatto ad un certo supporto.
Questi dati sono primariamente ad utilizzo dell’impianto per condurre il trattamento nel modo più corretto, ma diventano utilissimi per diagnosticare, anche preventivamente, condizioni indesiderate.
Formato del log
Il come i dati sono messi a disposizione dall’impianto è fondamentale per poterli trattare esternamente.
A seconda che si metta a disposizione un log su database o su file o ancora inviato per mezzo di protocolli come MQTT in JSON, si possono scegliere alcune codifiche differenti, ma la sostanza non cambia molto.
Le date, se adatabase, dovrebbero essere campi “datetime”, molto più facili da trattare. Se sono scambiate come “testo” allora il formato più facilmente riconoscibile è yyyy-mm-dd hh:mm:ss (anno, mese, giorno, ore, minuti e secondi).
Attenzione al timezone: è consigliabile utilizzare sempre UTC e successivamente, se necessario, adattare all’orario locale. L’impianto deve avere data e tempo tenuti aggiornati!
Ordini lavoro multipli
Se un “evento” (fine di un trattamento) è relativo a più ordini lavoro, ci sono due approcci:
- il “record” contiene i dati relativi al trattamento e una “lista” degli ordini lavoro coinvolti
- sono generati tanti record “uguali” per ogni ordine lavoro che era caricato sul supporto
Il primo approccio può rendere necessaria una disaggregazione del dato “esplodendolo” per ordine lavoro, operazione che è tipicamente poco immediata.
supporto 1; ordini 1, 2, 3; inizio carico; inizio trattamento; fine trattamento; fine scarico; percorso;
Il secondo approccio genera ovviamente dei dati “duplicati”, ma che sono facili da aggregare in fase di analisi del processo (inserendo un identificativo del supporto). Viceversa, è di aiuto quando si deve fare una analisi dal punto di vista dell’ordine lavoro perché, per ognuno, ho le informazioni puntutali.
supporto 1; ordine 1; inizio carico; inizio trattamento; fine trattamento; fine scarico; percorso; supporto 1; ordine 2; inizio carico; inizio trattamento; fine trattamento; fine scarico; percorso; supporto 1; ordine 3; inizio carico; inizio trattamento; fine trattamento; fine scarico; percorso;
L’identificativo del supporto che mi permette di “legare” i tre record che rappresentano un unico trattamento, è fondamentale. Non deve essere il generico numero fisico del supporto, ma un identificativo univoco del trattamento, può essere generato, ad esempio, usando il “timestamp” del momento di carico.
E’ sempre sconsigliato utilizzare un campo dati, come la data ed il tempo di inizio, ma di creare un campo surrogato apposito.